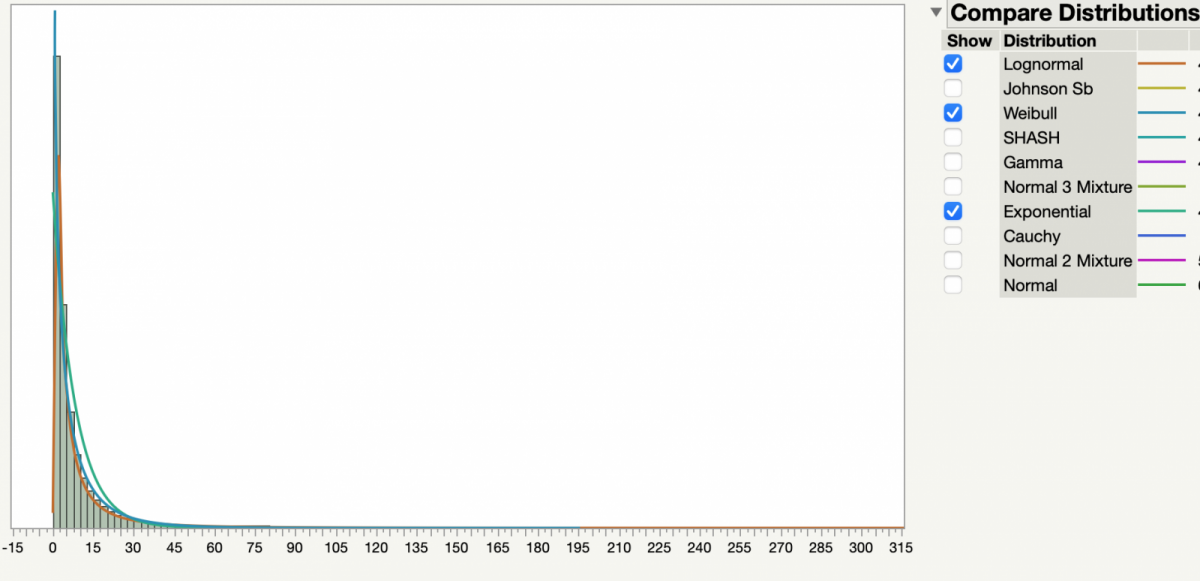
Since my last post on using NTHS dataset to fit people’s driving distances, I have made some further modifications:
(1) There are some very large TRPMILE data values, in the order of 1000 miles. While there are most likely valid data – After all, people do travel that far – I realize that this is not what I am after. I am mainly interested in day trips, while those thousand-mile trips are not. Therefore I decide to made a truncation at 300 miles.
(2) I also noticed that the vehicle data set includes other modes of transportation such as airplanes and commuter rails. After some debater, I decided to exclude them, and only includes TRPMILE for private vehicle. The main consideration is that they involve very large values and made fitting more difficult.
(3) While Excel is still competent, I decided to use JMP because it includes ready packages for fitting statistical distributions. JMP also has built-in procedures for selecting subsets.
The end result: Even truncating at 300 miles, fitting data into a single distribution with acceptance level of statistical significance is also difficult.
JMP tried all continuous distributions such as Lognormal, Weibull, and Exponential, and calculated that a Lognormal distribution provides the best fit.
However after I asked JMP to conduct a goodness-of-fit test, the result is the following:
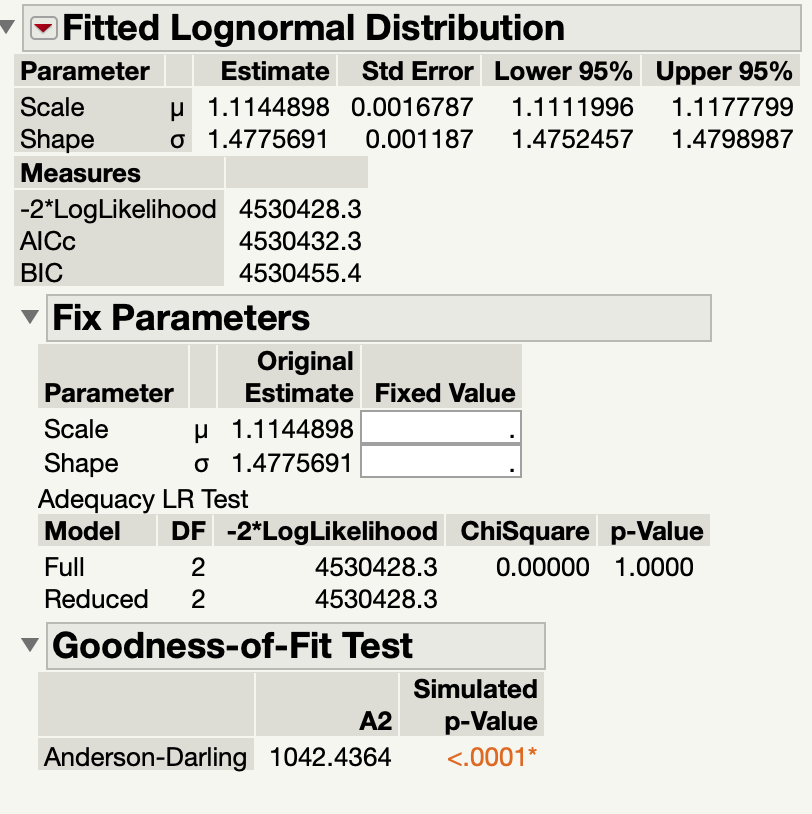
I had to do a quick catch-up to find out what an Anderson-Darling test is 🙂
The result says that it is not that good a fit (p-value is very small, thus reject Ho that the data is from a log-normal). The mismatch is due to, again, the very long tail. This tells me that there exist multiple underlying statistical distributions. For example, there may be one for daily trips, and another one for longer ‘irregular’ trips which people do not take on a daily basis.
But regardless, one thing remains clear and steadfast: Most of our driving trips are short. To be exact, 90% of the trips are less than 18 miles, 98% of trips are less than 46 miles.
Later on, we will examine the range anxiety based on this finding.
Leave a Reply
You must be logged in to post a comment.